Home
Team
Research
Publications
Data & Software
Job Offers
Talks
Teaching
Bachelor and Master Theses
Current Lecture/Seminar
Past Lectures
Research Projects
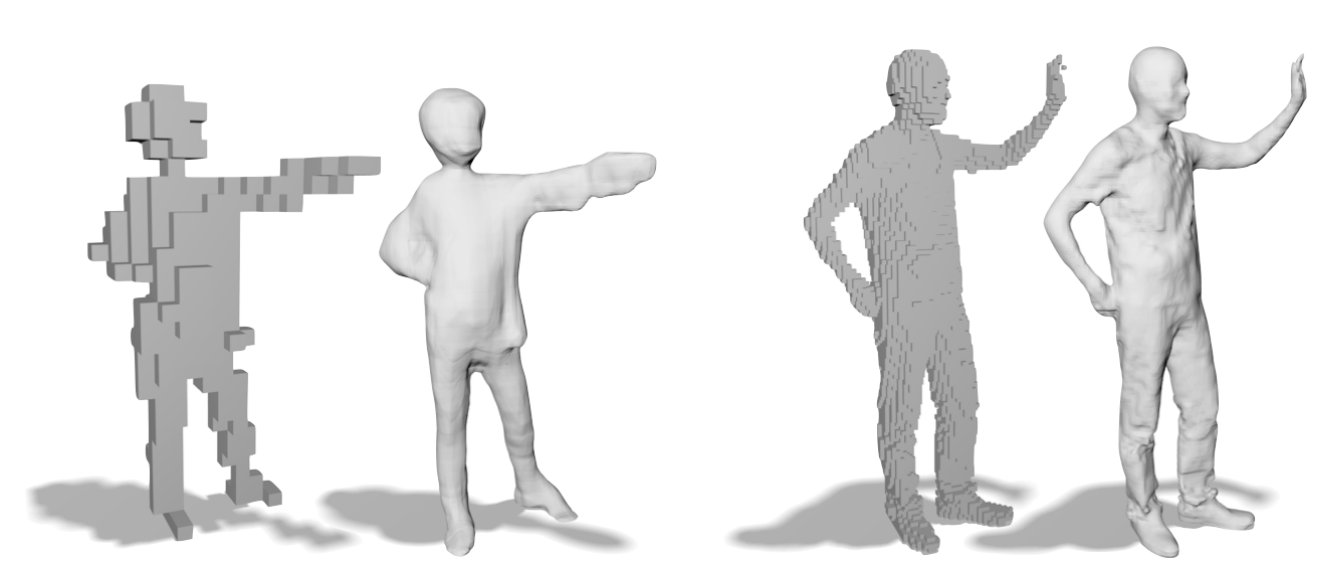
People in Clothing
3D Shape Learning
3D Human Body Registration
Human Motion from Wearables