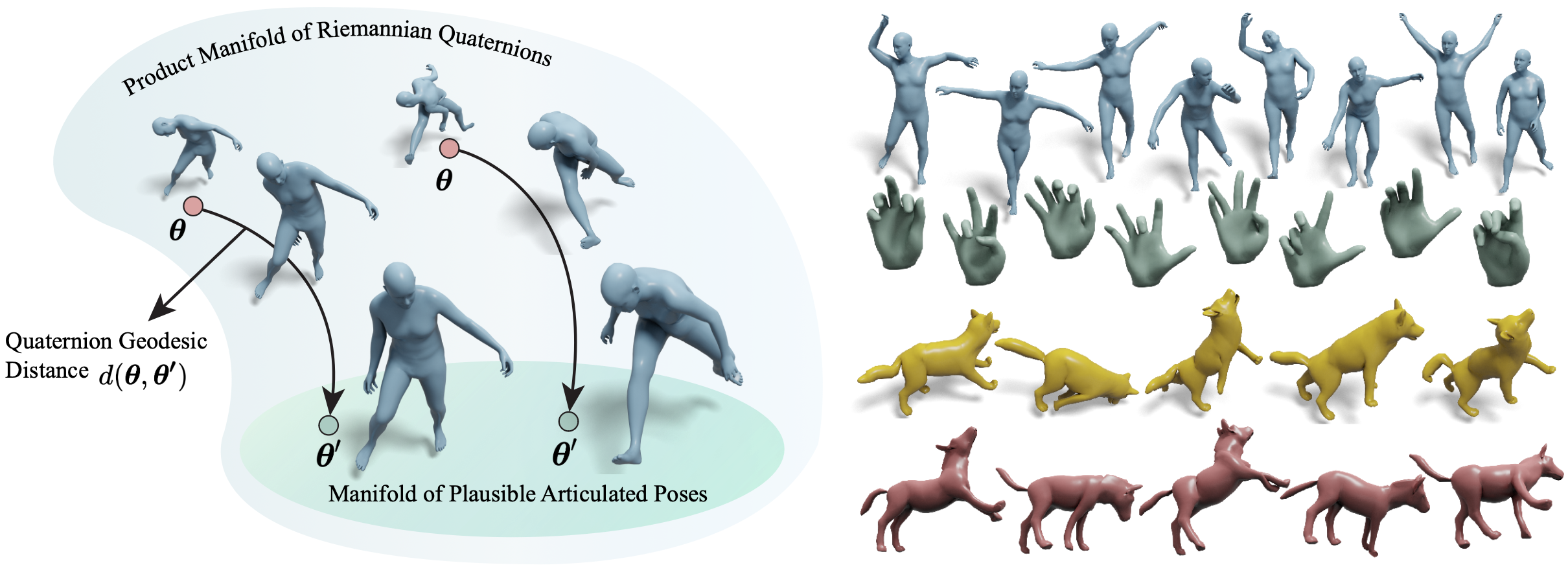
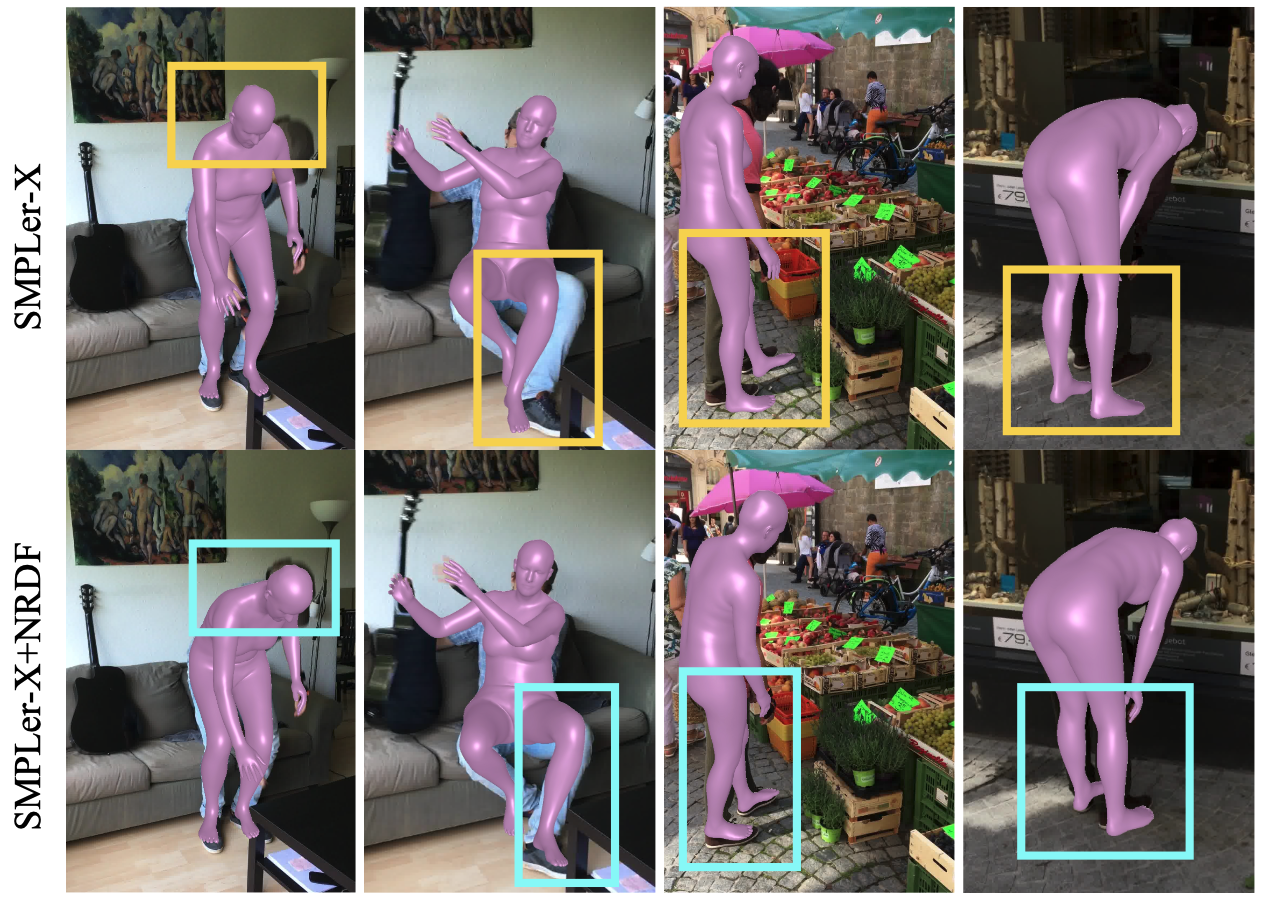
Faithfully modeling the space of articulations is a crucial task that allows recovery and generation of realistic poses, and remains a notorious challenge. To this end, we introduce Neural Riemannian Distance Fields (NRDFs), data-driven priors modeling the space of plausible articulations, represented as the zero-level-set of a neural field in a high-dimensional product-quaternion space. To train NRDFs only on positive examples, we introduce a new sampling algorithm, ensuring that the geodesic distances follow a desired distribution, yielding a principled distance field learning paradigm. We then devise a projection algorithm to map any random pose onto the level-set by an adaptive-step Riemannian optimizer, adhering to the product manifold of joint rotations at all times. NRDFs can compute the Riemannian gradient via backpropagation and by mathematical analogy, are related to Riemannian flow matching, a recent generative model. We conduct a comprehensive evaluation of NRDF against other pose priors in various downstream tasks, i.e., pose generation, image-based pose estimation, and solving inverse kinematics, highlighting NRDF’s superior performance. Besides humans, NRDF’s versatility extends to hand and animal poses, as it can effectively represent any articulation.