Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation
Xianghui Xie1, 2, 3, Bharat Lal Bhatnagar4, Jan Eric Lenssen3, Gerard Pons-Moll1,2,31 University of Tübingen, Germany
2 Tübingen AI Center, Germany
3 Max Planck Institute for Informatics, Saarland Informatics Campus, Germany
4 Meta Reality Labs
CVPR, 2024 (Highlight, Top ~2.8% of all submissions)

Abstract
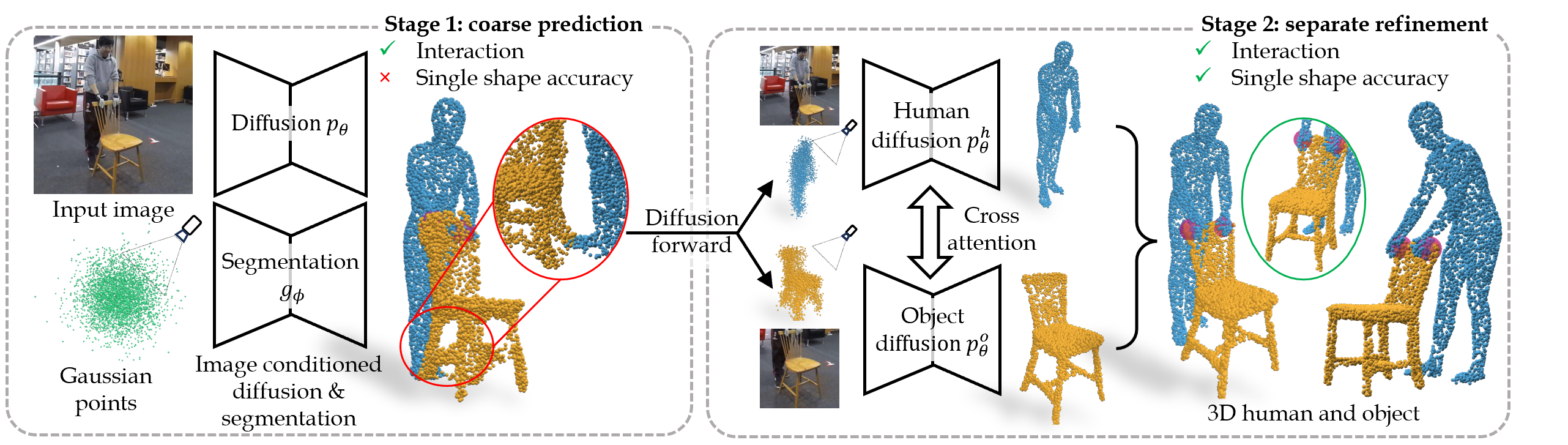
Reconstructing human-object interaction in 3D from a single RGB image is a challenging task and existing data driven methods do not generalize beyond the objects present in the carefully curated 3D interaction datasets. Capturing large-scale real data to learn strong interaction and 3D shape priors is very expensive due to the combinatorial nature of human-object interactions. In this paper, we propose ProciGen (Procedural interaction Generation), a method to procedurally generate datasets with both, plausible interaction and diverse object variation. We generate 1M+ human-object interaction pairs in 3D and leverage this large-scale data to train our HDM (Hierarchical Diffusion Model), a novel method to reconstruct interacting human and unseen objects, without any templates. Our HDM is an image-conditioned diffusion model that learns both realistic interaction and highly accurate human and object shapes. Experiments show that our HDM trained with ProciGen significantly outperforms prior methods that requires template meshes and that our dataset allows training methods with strong generalization ability to unseen object instances.
Key idea 1: generate large amount of interaction data with diverse shapes
Key idea 2: learn joint interaction space and individual human-object shape spaces separately.
Long narrated video
Generalization: without seeing any images from these datasets.
Generalization to the NTU-RGBD dataset.
Generalization to the SYSU-action dataset.
Generalization to in the wild COCO dataset.
Application: texturifying human and object separately using Text2txt.
Updates
Citation
@inproceedings{xie2023template_free,
title = {Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation},
author = {Xie, Xianghui and Bhatnagar, Bharat Lal and Lenssen, Jan Eric and Pons-Moll, Gerard},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
}
Acknowledgments

We thank RVH group members for their helpful discussions. This work is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - 409792180 (Emmy Noether Programme, project: Real Virtual Humans), and German Federal Ministry of Education and Research (BMBF): T¨ubingen AI Center, FKZ: 01IS18039A, and Amazon-MPI science hub. Gerard Pons-Moll is a member of the Machine Learning Cluster of Excellence, EXC number 2064/1 – Project number 390727645.The project was made possible by funding from the Carl Zeiss Foundation.