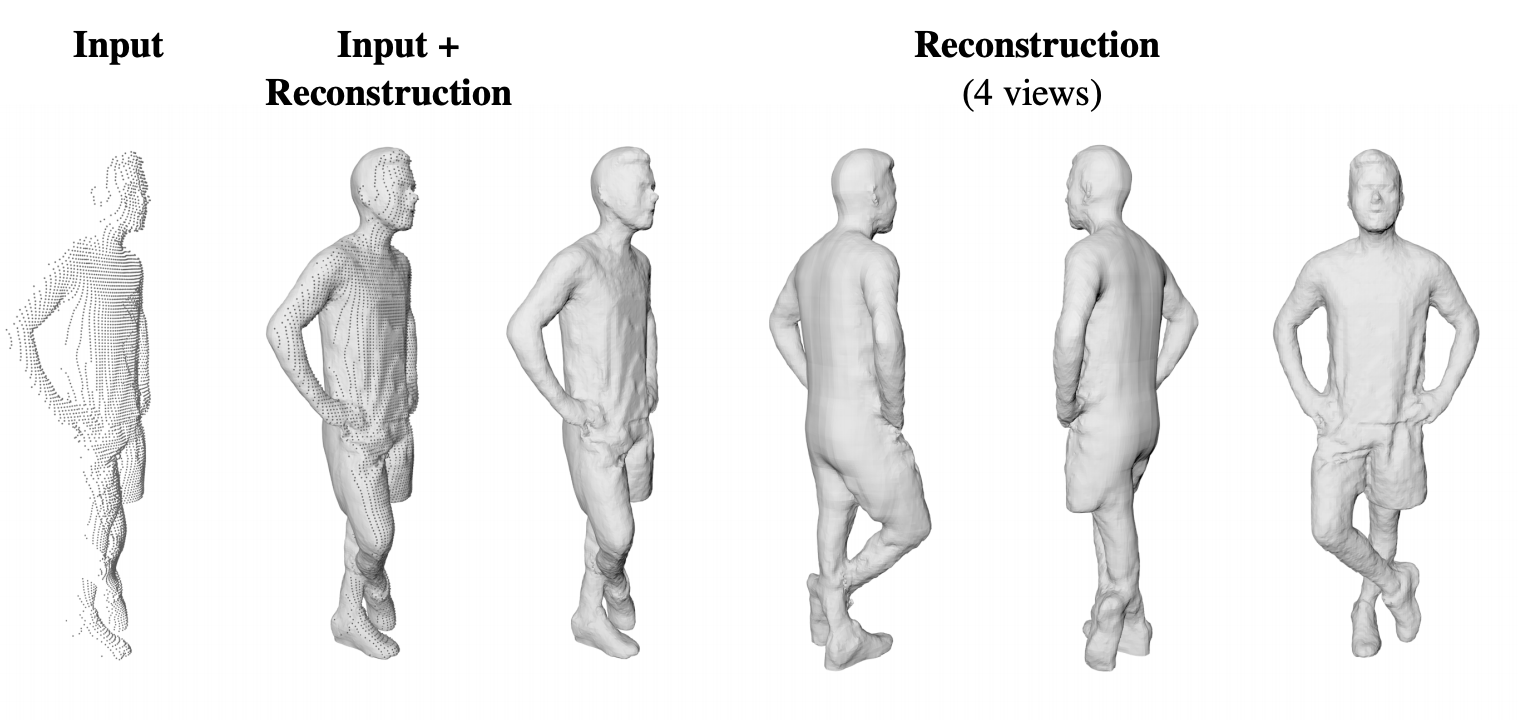
 Figure 1. Sparse voxel input (left) and full 3D shapes predicted by IF-Net [1].
Figure 1. Sparse voxel input (left) and full 3D shapes predicted by IF-Net [1].
Recently, implicit functions have shown to be a promising shape representation for learning thanks to its continuous property, breaking the previous barriers of output resolution. In IF-Net [1], we combined a learned implicit function represented by a 3D neural network, with a designed multi-scale 3D representation which preserves coarse-to-fine details of the input, to deliver continuous reconstructions from sparse 3D input data. IF-Net outperforms the state-of-the-art and is able to complete human body shapes given only a partial point cloud (Figure. 1).
While implicit functions modelled by deep neural networks are powerful, they only produce static surfaces that are not animatable. In [2], we proposed Implicit Part Network (IP-Net) which allows for detail-rich, controllable 3D reconstruction of clothed humans. Given a sparse 3D point cloud of a dressed person, it jointly predicts the outer 3D surface of the dressed person, the inner body surface, and the semantic correspondences to a parametric body model. Moreover, it allows to animate the detailed reconstruction with a human body model.
Although supervised correspondence prediction of humans has been proven effective [2], it relies on annotated data which is hard to obtain. Instead in LoopReg [3], we created a self-supervised, end-to-end learning framework to register a corpus of scans to a common 3D human model. A backward map, parameterized by a neural network, predicts the correspondence from every scan point to the surface of the human model. A forward map, parameterized by a human body model, transforms the corresponding points back to the scan based on model parameters (pose and shape), thus closing the loop. Results demonstrate that we can train LoopReg in a mainly self-supervised manner - following a supervised warm-start.
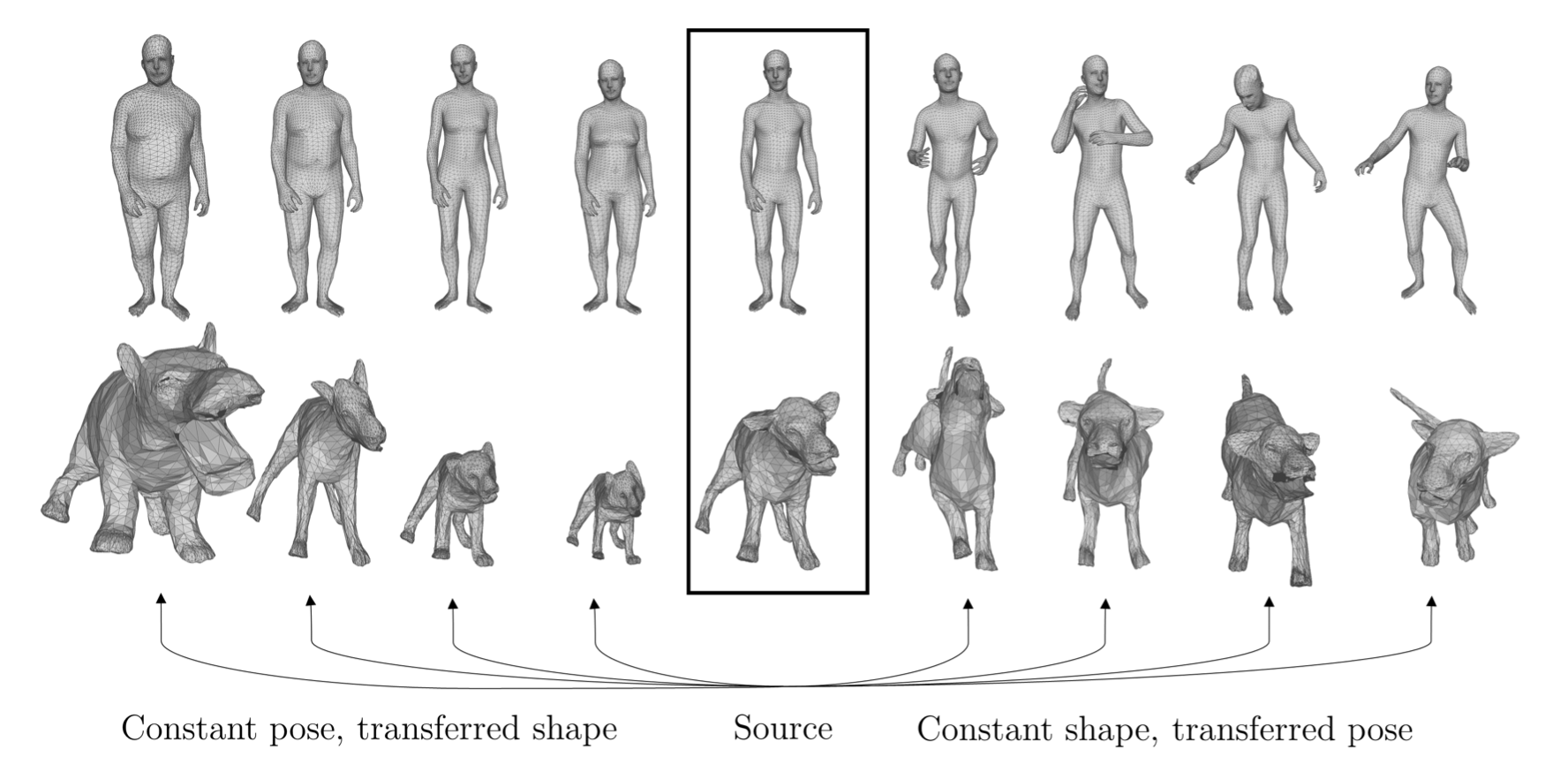 Figure 2. Shape and pose disentanglement produced by [4]. Left: meshes with the same pose but varying shapes. Right: meshes with the same subject identity but varying poses.
Figure 2. Shape and pose disentanglement produced by [4]. Left: meshes with the same pose but varying shapes. Right: meshes with the same subject identity but varying poses.
Humans can easily distinguish changes in body shape from changes in body pose. Many parametric human models also come with distinct shape and pose parameters, but they require domain knowledge to be defined and learned. In [4], we proposed a method to automatically learn shape and pose components from registered human meshes (Figure. 2). Our method can realistically transfer poses between different identities. It can be further generalized to other non-rigid shape categories such as human faces and animals.
References
-
Chibane, Julian, et al. "Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2020.
-
Bhatnagar, Bharat Lal, et al. "Combining implicit function learning and parametric models for 3d human reconstruction." European Conference on Computer Vision. Springer, Cham, 2020.
-
Bhatnagar, Bharat Lal, et al. "Loopreg: Self-supervised learning of implicit surface correspondences, pose and shape for 3d human mesh registration." Advances in Neural Information Processing Systems 33 (2020).
-
Zhou, Keyang, et al. "Unsupervised Shape and Pose Disentanglement for 3D Meshes." European Conference on Computer Vision. Springer, Cham, 2020.