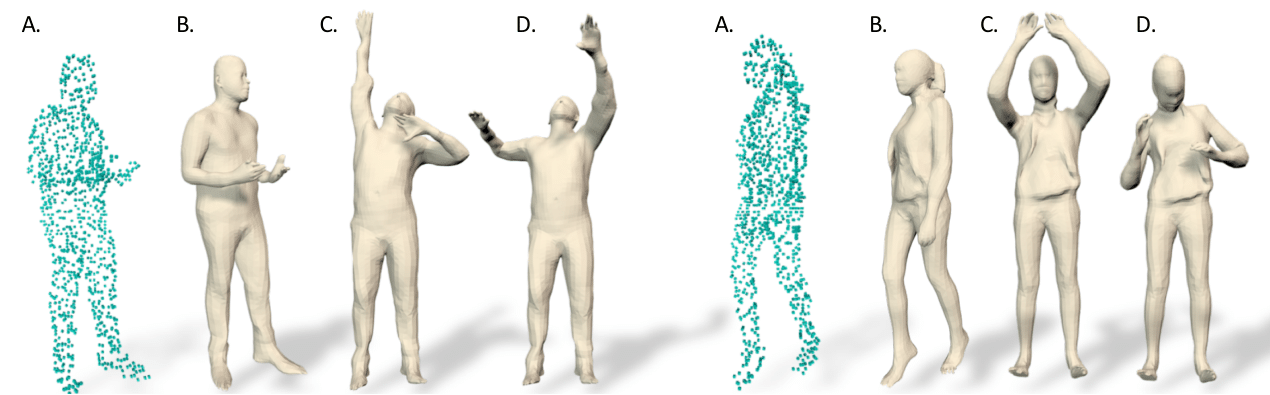
 Figure 1. Single view point cloud and registration using IP-Net. Given a single view point cloud (A), IP-Net can be used to predict the missing shape and register SMPL+D (B) to it. This allows us to control the registration with novel poses (C, D).
Figure 1. Single view point cloud and registration using IP-Net. Given a single view point cloud (A), IP-Net can be used to predict the missing shape and register SMPL+D (B) to it. This allows us to control the registration with novel poses (C, D).
Statistical human body models are key ingredients in studying, manipulating and animating digital humans. We proposed SMPL [1], a human body model built upon linear blend skinning. To account for body shape variations and pose-dependent shape variations, SMPL learns shape and pose blendshapes from a large number of aligned scans. SMPL has a linear formulation and it is compatible with commercial rendering engines, making it a valuable tool for many research projects in the vision and graphics community.
Realistic digital humans exhibit various soft-tissue deformations when performing motions. In Dyna [2], we learned a low-dimensional linear subspace of soft-tissue deformations, which is related to pose coefficients of the underlying body model. Dyna significantly advances the state-of-the-art in terms of animation realism.
Registering a 3D human body model to human scans is a challenging problem due to noise and missing regions in scans. In IP-Net [3], we utilized implicit functions modelled by deep neural networks to reconstruct detail-rich scan surfaces. The proposed method can reconstruct humans in clothing from sparse point clouds or even from single-view depth images, see Figure. 1. Another difficulty for registration with a learning-based approach is the lack of annotated training samples. In LoopReg [4], we cast registration as a differentiable end-to-end formulation by diffusing the SMPL blending function to the whole 3D space. This self-supervised model only requires a small set of registered scans to warm-start and it becomes more accurate after processing more raw scans.
 Figure 2. DFaust exploits consistency in texture over time intervals and deals with temporal offsets between shape and texture capture.
Figure 2. DFaust exploits consistency in texture over time intervals and deals with temporal offsets between shape and texture capture.
Applying machine learning to animation, motion prediction and motion synthesis requires a large amount of registered 4D motion data. We developed a novel 4D registration technique by exploiting the temporal consistency of texture. With this approach, we collected a dynamic 4D human dataset DFaust [5], which contains 40,000 raw and aligned meshes (Figure. 2). Existing marker-based human capture datasets vary in size, skeleton structure and annotation details, hence cannot be jointly used. Therefore we introduced AMASS [6], a large-scale human motion capture dataset that unifies 15 mocap datasets under the same parametrization. We achieved this by solving a sophisticated optimization problem to fit the body model to sparse marker sets.
References
-
Loper, Matthew, et al. "SMPL: A skinned multi-person linear model." ACM transactions on graphics (TOG) 34.6 (2015): 1-16.
-
Pons-Moll, Gerard, et al. "Dyna: A model of dynamic human shape in motion." ACM Transactions on Graphics (TOG) 34.4 (2015): 1-14.
-
Bhatnagar, Bharat Lal, et al. "Combining implicit function learning and parametric models for 3d human reconstruction." European Conference on Computer Vision. Springer, Cham, 2020.
-
Bhatnagar, Bharat Lal, et al. "Loopreg: Self-supervised learning of implicit surface correspondences, pose and shape for 3d human mesh registration." Advances in Neural Information Processing Systems 33 (2020).
-
Bogo, Federica, et al. "Dynamic FAUST: Registering human bodies in motion." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
-
Mahmood, Naureen, et al. "AMASS: Archive of motion capture as surface shapes." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.