Abstract
In everyday lives, humans naturally modify the surrounding environment through interactions, e.g., moving a chair to sit on it. To reproduce such interactions in virtual spaces (e.g., metaverse), we need to be able to capture and model them, including changes in the scene geometry, ideally from ego-centric input alone (head camera and body-worn inertial sensors). This is an extremely hard problem, especially since the object/scene might not be visible from the head camera (e.g., a human not looking at a chair while sitting down, or not looking at the door handle while opening a door). In this paper, we present HOPS, the first method to capture interactions such as dragging objects and opening doors from ego-centric data alone. Central to our method is reasoning about human-object interactions, allowing to track objects even when they are not visible from the head camera. HOPS localizes and registers both the human and the dynamic object in a pre-scanned static scene. HOPS is an important first step towards advanced AR/VR applications based on immersive virtual universes, and can provide human-centric training data to teach machines to interact with their surroundings.
The research question
Given an ego-centric view, data from a body-mounted IMU and a 3D static scan of the environment, the research question we address here is: Can we estimate human and object coherently with the scene?
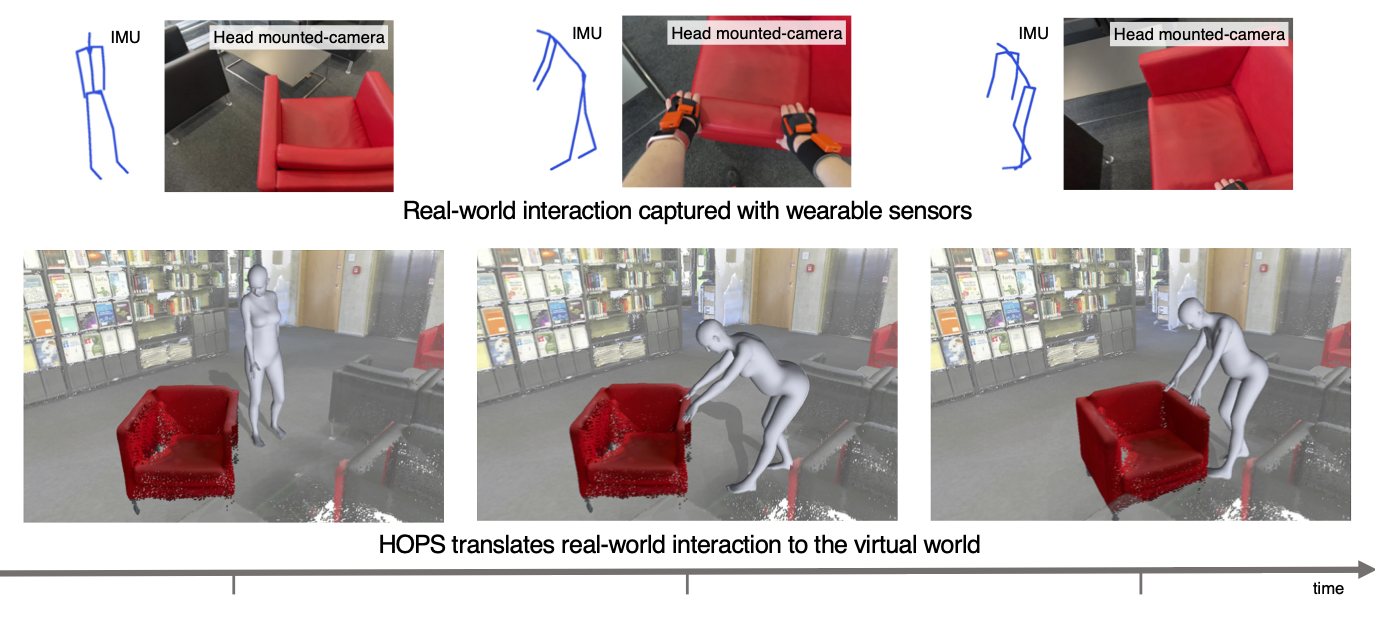
We propose HOPS – a method of capturing human-object interactions using only a wearable camera and inertial sensors. Combining visual localization cues and our novel interaction model, HOPS tracks the human and the object pose even when it is not visible.
Paper, code and data

The problem
Main limitation of previous body-mounted capturing systems is their inability to register dynamic scene changes such as object movement, door opening and so on. Our goal is to fix that by modeling human-object interaction.
Interaction challenges
Such a task imposes different kinds of challenges, and interaction modeling is the toughest one. During the interaction, the object can be barely visible, or oppositely, it can obstruct the whole view, making it difficult to even tell whether the object is moving. This makes it hard to localize the object and model the interaction.
Our solution – HOPS
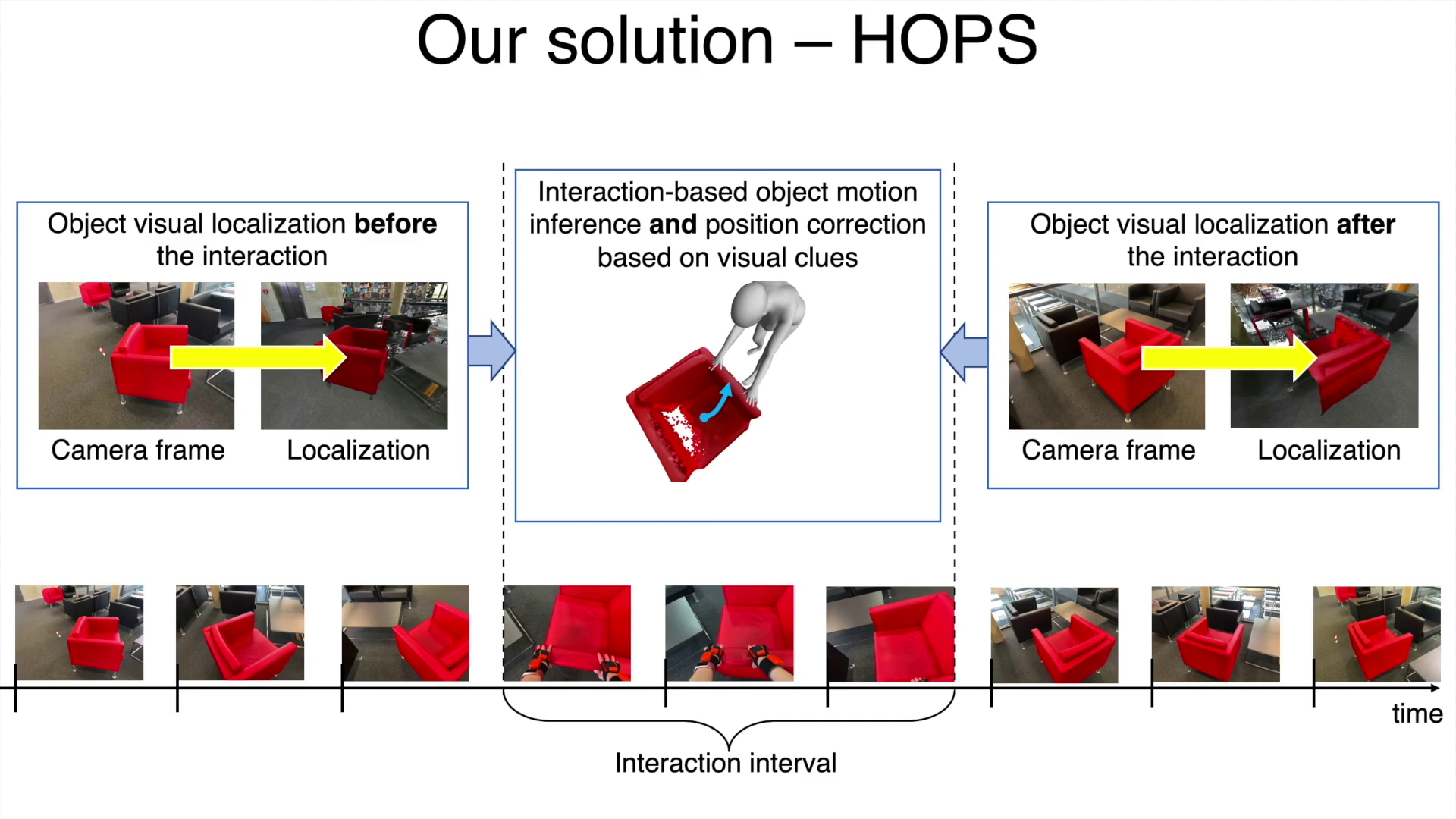
Our key idea: using interaction reasoning we can track the object even when it is not visible in the head camera.
Results
Citation
@inproceedings{guzov22hops,
title = {Visually plausible human-object interaction capture from wearable sensors},
author = {Guzov, Vladimir and Sattler, Torsten and Pons-Moll, Gerard},
booktitle = {arXiv},
year = {2022}
}Acknowledgments
We thank Bharat Bhatnagar, Verica Lazova, Ilya Petrov and Garvita Tiwari for their help and feedback. This work is partly funded by the DFG - 409792180 (Emmy Noether Programme, project: Real Virtual Humans), German Federal Ministry of Education and Research (BMBF): Tübingen AI Center, FKZ: 01IS18039A and ERC Consolidator Grant 4DRepLy (770784), the EU Horizon 2020 project RICAIP (grant agreeement No.857306), and the European Regional Development Fund under project IMPACT (No. CZ.02.1.01/0.0/ 0.0/15 003/0000468). Gerard Pons-Moll is a member of the Machine Learning Cluster of Excellence, EXC number 2064/1 - Project number 390727645. Website is based on the StyleGAN3 website template.