Capture from Images
 Figure 1. In [2] we can reconstruct human body shape, clothing and appearance from a single monocular video. The core of the method is a geometric optimization algorithm which brings pose-varying silhouettes into a an unposed reference frame. This allows to fuse the shape information of every frame.
Figure 1. In [2] we can reconstruct human body shape, clothing and appearance from a single monocular video. The core of the method is a geometric optimization algorithm which brings pose-varying silhouettes into a an unposed reference frame. This allows to fuse the shape information of every frame.
Alldieck et al. [1] proposed the first method capable of reconstructing people and their clothing from a single RGB video without using pre-scanned templates. We further extended the approach in [2] by integrating shading cues and a graph based optimization for body texture generation from a single RGB video (Figure. 1). While accurate, these approaches [1][2] are based on non-linear optimization, which is prone to poor initialization and is typically slow. As a result in [3], we combined the advantages of deep learning and model-based fitting, and proposed Octopus with both top-down and bottom-up streams. Octopus accurately reconstructs 3D shape, hair and clothing in less than 10 seconds.
In MGN [4], we proposed the first model capable of inferring human body and layered garments on top as separate meshes from images directly, which allows full control over body shape, texture and geometry of clothing. Additionally, MGN enables real world applications like 3D virtual try-on using only RGB images.
While there has been extensive work on 3D human pose and shape recovery from a single image, few work attempted to address the problem of predicting a complete texture of a person from a single image. [5] turns a difficult 3D inference problem into a simpler 2D image-to-image translation task. Given partial texture and segmentation layout maps derived from the input image, our model predicts complete segmentation map, complete texture map, and a displacement map. The predicted maps can be applied to the SMPL model and we can obtain a full textured 3D avatar of the person.
Modeling and Animation
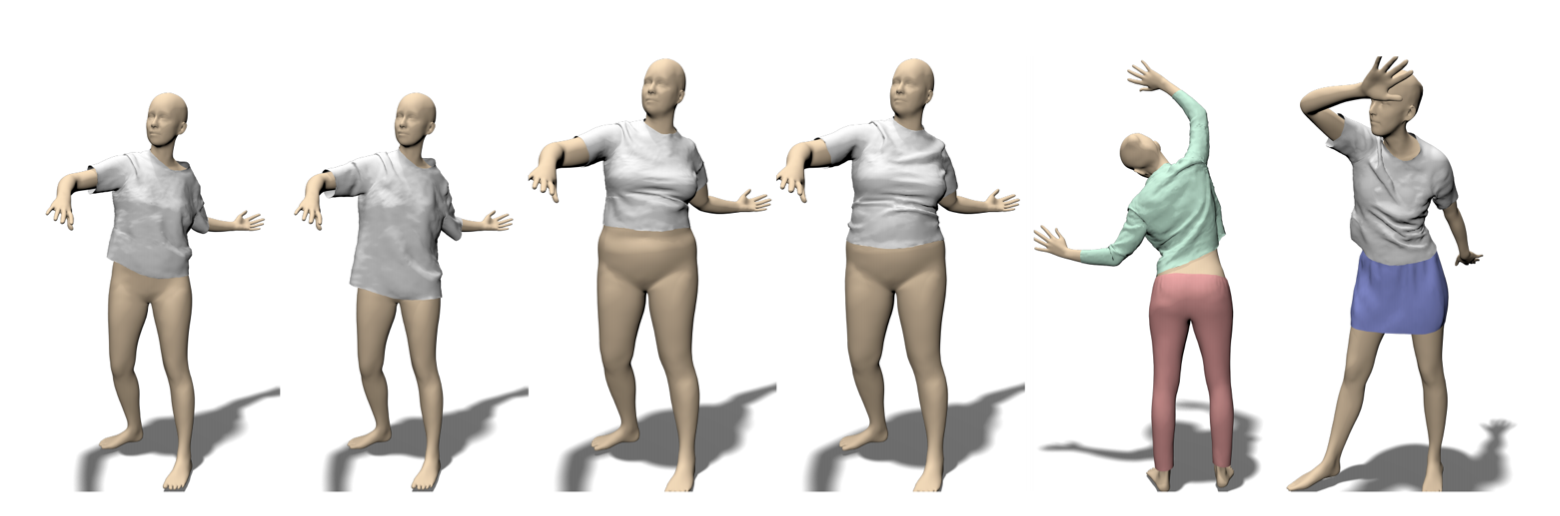 Figure 2. 3D clothing deformation predicted from TailorNet [7], From the left: the first two avatars show two different styles on the same shape, the following two show the same two styles on another shape, and the last two avatars illustrate the results of TailorNet on different garments.
Figure 2. 3D clothing deformation predicted from TailorNet [7], From the left: the first two avatars show two different styles on the same shape, the following two show the same two styles on another shape, and the last two avatars illustrate the results of TailorNet on different garments.
People typically wear multiple pieces of clothing at a time. To estimate the shape of such clothing, track it over time, and render it realistically, each garment must be segmented from the others and the body. [6] approached as one of the pioneer work in the field using a statistical multi-part 3D model of clothed bodies. It automatically segments each piece of clothing, estimates the minimally clothed body shape and pose under the clothing, and tracks the 3D deformations of the clothing over time.
Animating digital humans in clothing has numerous applications in 3D content production, games, entertainment and virtual try-on. The most prominent approach remains to be physics-based simulation which is laborious, time-consuming and requires expert knowledge. To address such challenges, we proposed the first joint model of clothing style, pose and shape variation [7], which is more than 1000 times faster than traditional physics-based simulations (Figure. 2).
In [8], we introduced the first model of clothing deformation as a function of garment size label, which is learned from real data. It has tremendous applications in the fashion industry. Moreover, we captured the first large-scale dataset of 2000 scans of real clothing with varying clothing size, style and body shape.
Previous works for human and clothing model use mesh based representation and have two major limitations, 1) strenuous and error-prone data processing, and 2)limited to fixed topology. Recent advances in 3D shape representation using neural implicits have been shown to represent 3D shape with much more details and are not limited by fixed topology. We use neural implicits in [9], to learn an animatable model of human or human with clothing. We present Neural Generalized Implicit Functions (Neural-GIF), to animate people in clothing as a function of the body pose. Given a sequence of scans of a subject in various poses, we learn to animate the character for new poses. We draw inspiration from template-based methods[10], which factorize motion into articulation and nonrigid deformation, but generalize this concept for implicit shape learning to obtain a more flexible model. Our formulation allows the learning of complex and non-rigid deformations of clothing and soft tissue, without computing a template registration as it is common with current mesh based approaches. We also extend our model to multiple shape setting.
References
-
Alldieck, Thiemo, et al. "Video Based Reconstruction of 3D People Models." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
-
Alldieck, Thiemo, et al. "Detailed Human Avatars from Monocular Video." International Conference on 3D Vision (3DV), 2018.
-
Alldieck, Thiemo, et al. "Learning to reconstruct people in clothing from a single rgb camera." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
-
Bhatnagar, Bharat Lal, et al. "Multi-Garment Net: Learning to Dress 3D People from Images." IEEE International Conference on Computer Vision (ICCV), 2019.
-
Lazova, Verica Lal, et al. "360-Degree Textures of People in Clothing from a Single Image." International Conference on 3D Vision (3DV), 2019.
-
Pons-Moll, Gerard, et al. "ClothCap: Seamless 4D Clothing Capture and Retargeting." ACM Transactions on Graphics (TOG) 36.4 (2017).
-
Patel, Chaitanya and Liao, Zhouyingcheng, et al. "TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style." Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2020.
-
Tiwari, Garvita, et al. "SIZER: A Dataset and Model for Parsing 3D Clothing and Learning Size Sensitive 3D Clothing." European Conference on Computer Vision. Springer, Cham, 2020.
-
Tiwari, Garvita, et al. "Neural-GIF: Neural Generalized Implicit Functions for Animating People in Clothing." International Conference on Computer Vision (ICCV), 2021.
-
Loper, Matthew, et al. "SMPL: A skinned multi-person linear model." ACM transactions on graphics (TOG) 34.6 (2015): 1-16.