Abstract
The intimate entanglement between objects affordances and human poses is of large interest, among others, for behavioural sciences, cognitive psychology, and Computer Vision communities. In recent years, the latter has developed several object-centric approaches: starting from items, learning pipelines synthesizing human poses and dynamics in a realistic way, satisfying both geometrical and functional expectations. However, the inverse perspective is significantly less explored: Can we infer 3D objects and their poses from human interactions alone? Our investigation follows this direction, showing that a generic 3D human point cloud is enough to pop up an unobserved object, even when the user is just imitating a functionality (e.g., looking through a binocular) without involving a tangible counterpart. We validate our method qualitatively and quantitatively, with synthetic data and sequences acquired for the task, showing applicability for XR/VR.
Our goal
Given the unordered human point cloud and, optionally, an object class as an input, we want to estimate the position of the object.

Motivation
We find inspiration in Gestalt psychology, particularly in the reification principle: the mind completes an object even when the
visual information is missing. The combination of individual body parts allows us to visualize the binoculars in the example below.
Thus, we pose a following research question: Can we infer 3D objects and their poses from human interactions alone?
Method
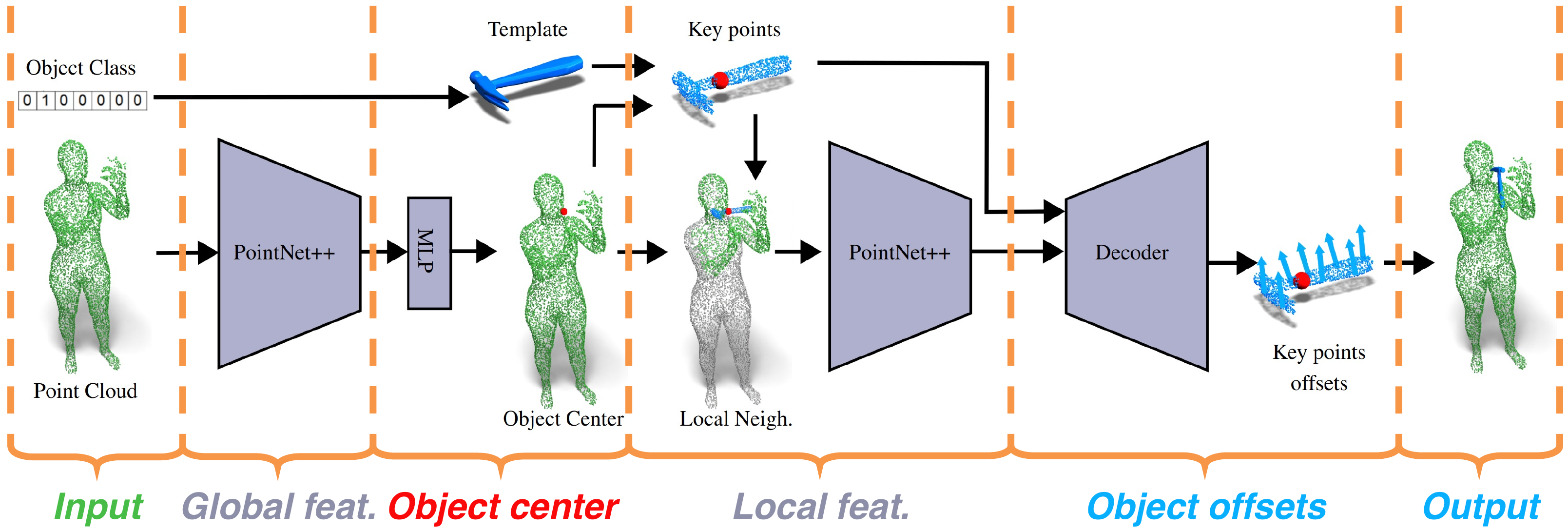
Our method work as follows: global features are extracted using PointNet++ encoder from an input point cloud, then an object center is predicted. Next, object key points in the canonical pose are shifted to the center and coupled with the local neighbourhood of the input point cloud around it, are used to extract per-point local features using second PointNet++ encoder. Then, local and global features are used to decode per-point offsets for object key points. Finally, the object mesh is posed using the predicted offsets.
Analysis
We analyze the importance of points for prediction using an algorithm from T. Zheng et al. ICCV'19 for point cloud saliency estimation. We iteratively cast the input through the network and compute a loss on the output, then we modify the input using the backpropagated gradient. The most influential points are highlighted in red. We observe that the contact region is always essential to infer the correct object location. However, feet play a crucial role in all the reported cases, since they provide information about the human position and the consequent pose of the body. Another highlighted region is the head: different orientations give clues about object location and body posture.
Results
The method is evaluated on GRAB and BEHAVE.
Moreover, we test Object pop-up on raw point clouds from BEHAVE and qualitatevly evaluate the method on data manually recorded with IMU sensors.
Additionally we explore temporal smoothing of predictions to remove jittering of per-frame predictions and increase accuracy.
Citation
@inproceedings{petrov2023popup,
title={Object pop-up: Can we infer 3D objects and their poses from human interactions alone?},
author={Petrov, Ilya A and Marin, Riccardo and Chibane, Julian and Pons-Moll, Gerard},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}Acknowledgments
Special thanks to the RVH team and reviewers, their feedback helped improve the manuscript. We also thank Omid Taheri for the help with GRAB objects. This work is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - 409792180 (EmmyNoether Programme, project: Real Virtual Humans) and the German Federal Ministry of Education and Research (BMBF): Tübingen AI Center, FKZ: 01IS18039A. G. Pons-Moll is a member of the Machine Learning Cluster of Excellence, EXC number 2064/1 – Project number 390727645. The authors thank the International Max Planck Research School for Intelligent Systems (IMPRS-IS) for supporting I. Petrov. R. Marin is supported by an Alexander von Humboldt Foundation Research Fellowship. The project was made possible by funding from the Carl Zeiss Foundation. Website is based on StyleGAN3 and Nerfies websites.