Unsupervised Shape and Pose Disentanglement for 3D Meshes
Keyang Zou, Bharat Lal Bhatnagar, Gerard Pons-MollMax Planck Institute for Informatics, Saarland Informatics Campus, Germany
Paper, Supplementary, Code, Video, Arxiv
Abstract
Parametric models of humans, faces, hands and animals have been widely used for a range of tasks such as image-based reconstruction, estimating correspondence between 3D shapes, or animation. Their key strength is the ability to factor surface variations into shape and pose dependent components. The process of learning such models requires lots of expert knowledge and hand-defined object specific constraints, making the learning approach unscalable to novel object categories. In this paper, we present a simple yet effective approach to learn disentangled shape and pose representations in an unsupervised setting. We use a combination of self-consistency and cross-consistency constraints to learn pose and shape space from a dataset of registered meshes. We additionally incorporate as-rigid-as-possible surface deformation(ARAP) into the training loop to avoid degenerate solutions. We demonstrate the usefulness of learned representations through a number of tasks including pose transfer and shape retrieval. The experiments on datasets of 3D humans, faces, hands and animals demonstrate the generality of our approach.
Pose Transfer
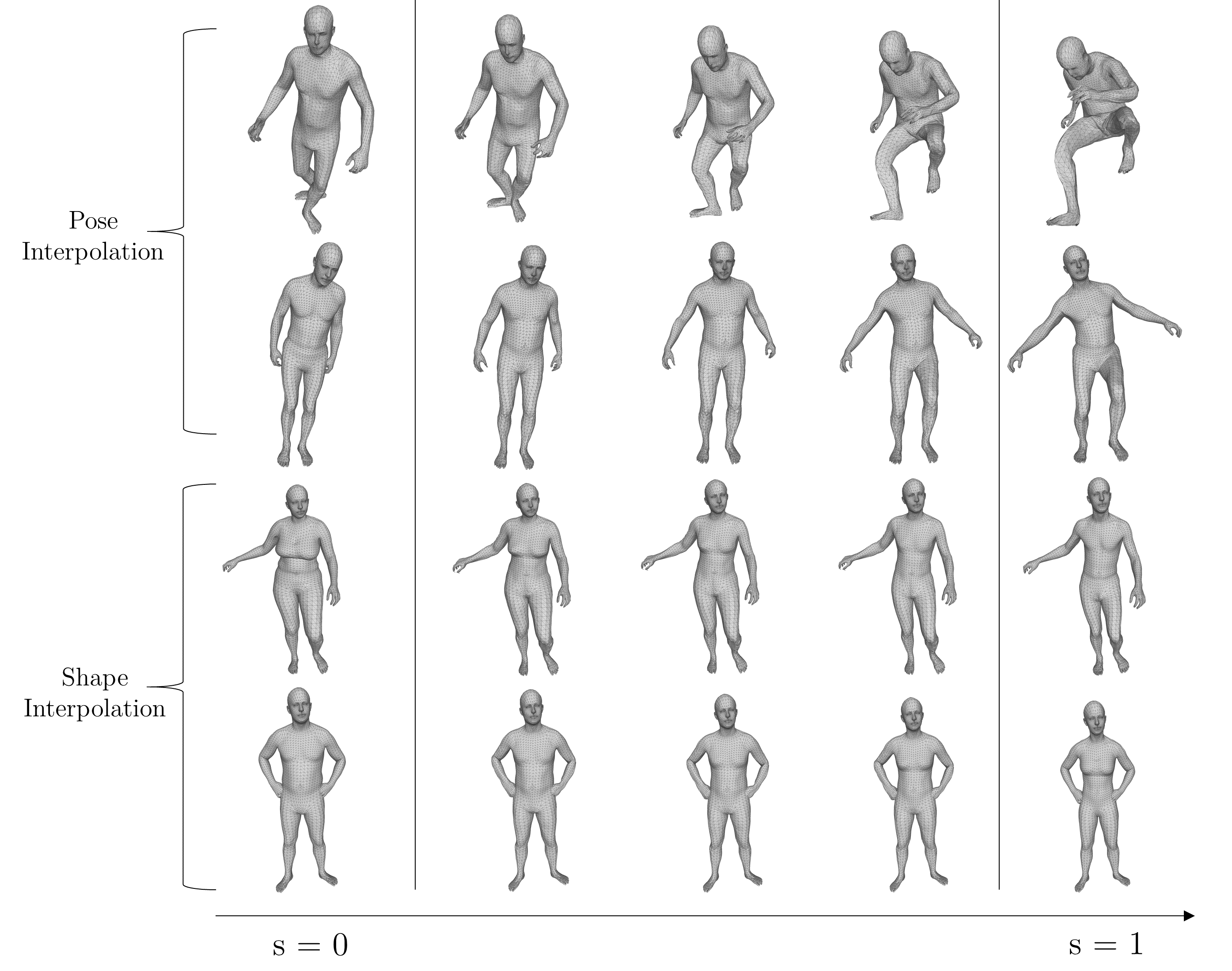
Pose & Shape Interpolation
Code
Citation
@InProceedings{keyang20unsupervised,
author = {Zhou, Keyang and Bhatnagar, Bharat Lal and Pons-Moll, Gerard},
title = {Unsupervised Shape and Pose Disentanglement for 3D Meshes},
booktitle = {The European Conference on Computer Vision (ECCV)},
month = {August},
year = {2020},
}